14. Quantization#
14.1. Pre-reading#
Watch the video DeepLearningAI-Quantization_Fundamentals-Handling_Big_Models posted in Teams
Objectives#
Describe different data types supported by ARM, PyTorch, and TensorFlow Lite.
Quantize data into different data types.
Assess the impact on memory usage of quantization.
%pip install -q torch
import torch
14.2. Data Types and Sizes#
*Some of this content is from DeepLearning AI “Quantization Fundamentals”
PyTorch and TensorFlow both support various data types. Many - but not all - of these are familiar to you from your experience with C programming.
This course has thusfar focussed on TensorFlow, but PyTorch has better support for this sort of stuff, particularly as HuggingFace and the rest of the community continues to favor PyTorch over TensorFlow.
Integer Types#
Unsigned go from \([0, 2^N -1]\)
Signed are two’s complement and go from \([-2^{N-1}, 2^{N-1}-1]\)
# Information of `8-bit unsigned integer`
torch.iinfo(torch.uint8)
# Information of `8-bit (signed) integer`
torch.iinfo(torch.int8)
# TODO: Information of `16-bit (signed) integer
# TODO: Information of `32-bit (signed) integer
# TODO: Information of `64-bit (signed) integer
Floating Point Types#
The decimal “floats”, and the number is expressed as a base and exponent.
IEEE 754 single-precision FP32 has:
1 sign bit
8 exponent bits
23 fraction bits
But there are other formats!
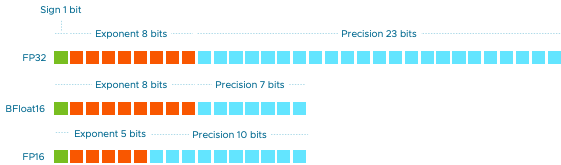
Python defaults to FP64 for float data.
# Information of `64-bit floating point`
torch.finfo(torch.float64)
# Information of `32-bit floating point`
torch.finfo(torch.float32)
# TODO: Information of `16-bit floating point`
# by default, python stores float data in fp64
value = 1 / 3
format(value, ".60f")
tensor_fp64 = torch.tensor(value, dtype=torch.float64)
tensor_fp32 = torch.tensor(value, dtype=torch.float32)
tensor_fp16 = torch.tensor(value, dtype=torch.float16)
tensor_bf16 = torch.tensor(value, dtype=torch.bfloat16)
print(f"fp64 tensor: {format(tensor_fp64.item(), '.60f')}")
print(f"fp32 tensor: {format(tensor_fp32.item(), '.60f')}")
print(f"fp16 tensor: {format(tensor_fp16.item(), '.60f')}")
print(f"bf16 tensor: {format(tensor_bf16.item(), '.60f')}") # More on this below
bfloat16#
Developed by Google Brian, bfloat16 has approximately the same dynamic range as 32-bit float, but only has 8-bit precision instead of float32’s 24-bits of precision.
Most machine learning applications do not require single-precision, but simply casting to FP16 sacrifices dynamic range. The smaller size of bfloat16 numbers allow for more efficient memory usage and calculation speed compared to float32.
See bfloat16 Wikipedia for more!
# Information of `16-bit brain floating point (bfloat16)`
torch.finfo(torch.bfloat16)
bfloat16 on ARM processors#
Recent Arm processors support the BFloat16 (BF16) number format in PyTorch. BFloat16 provides improved performance and smaller memory footprint with the same dynamic range. You might experience a drop in model inference accuracy with BFloat16, but the impact is acceptable for the majority of applications. ~ ARM Learn: PyTorch
To check if your system includes BFloat16, use the lscpu command:
# Will print flags if your processor supports BFloat16
# If result is blank you do not have a processor with BFloat16.
!lscpu | grep bf16
Fixed Point Types#
We previously discussed the CMSIS support in ARM processors and how they operate on the Q number format.
A Q number has a sign bit followed by a fixed number of bits to represent the integer value.
The remaining bits represent the fractional part of the number.
Signed Q numbers are stored as two’s complement values.
A Q number is typically referred to by the number of fractional bits it uses so Q7 has 7 fractional places.
The fractional bits are represented as negative powers of two.
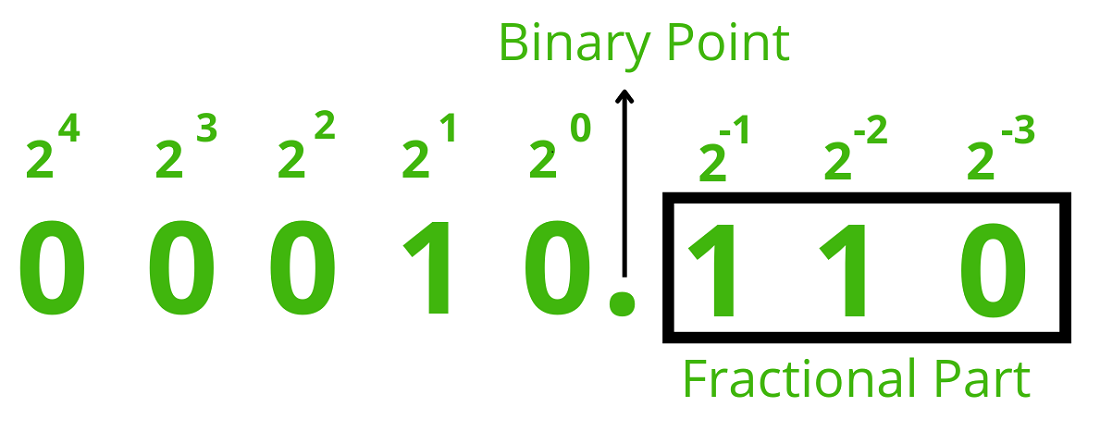
The CMSIS DSP library functions are designed to take input values in the range [-1, 1), so the fractional section takes all the bits of the data type minus one bit that is used as a sign bit.
CMSIS DSP Type Def |
Q number |
C Type |
|---|---|---|
Q31_t |
Q31 |
Int 32 |
Q15_t |
Q15 |
Int 16 |
Q7_t |
Q7 |
Int 8 |
Tip
Many neural networks expect inputs in the normalized range [-1, 1)!
Neither TensorFlow or PyTorch directly support fixed-point numbers
LiteRT uses floating-point numbers because they are more widely supported and almost as fast.
Ultra-optimized libraries, such as some of those from EdgeImpulse do use these functions.
Computation with Q Numbers#
Like all binary number representations, fixed-point numbers are just a collection of bits. There is no way of knowing the existence of the binary point except through agreement of those people interpreting the number. ~ Digital Design and Computer Architecture, ARM Edition
Because the placement of the decimal is just an agreement, int8 and Q7 can use much of the same hardware!
The biggest difference is how overflows are handled for integers versus handling saturations for Q numbers.
Let’s ask ChatGPT for an example of multiply-accumulate with the two data types! And then have me adjust it…
int8 Example#
Input:
A = -50 (int8) →
11001110B = 30 (int8) →
00011110Accumulator (int16) = 500 →
00000001 11110100
Multiply: \(-50 * 30 = -1500\) →
11111010 00100100(16-bit two’s complement)Accumulate: \(500 + -1500 = -1000\) →
11111100 00001000
Q7 Example#
Input:
A = -0.390625 (Q7) →
11001110(same binary as int8)B = 0.234375 (Q7) →
00011110(same binary as int8)Accumulator = 3.90625 (Q7 but with more integer bits) →
00000001 11110100(same binary as int16)
Multiply: \(-0.390625 * 0.234375 = -0.091552734375\) →
11111010 00100100(still the same binary, but is -11.71875 in Q7!)Q7 format shift adjustment: \(>>7\) →
11110100= -0.09375 (close to -0.09155)Accumulate: \(3.90625 + -0.09375 = 3.8125\) →
00000011 11101000(why is this so different than the int8?)
Conclusion: The final results are very different, but the thing to keep in mind is the scaling of Q7. The range of int8 is \(2^7=128\) times that of Q7, so we can compare the two by multiplying Q7 by 128.
In this case, the int8 accumulator changed by a factor of \(\frac{-1000-500}{500} = -3.0)\)
Meanwhile, the Q7 accumulator changed by a factor of \(\frac{488-500}{500} = -0.024)\), which if you scale by 128 is \(3.072\), very close to the int8 relative change!
You can play around with this using chummersone Q-format converter
14.3. Conversion between types#
Downcasting#
Downcasting converts a type of higher precision to lower precision. It results in a loss of data.
The torch.Tensor.to() method:
Allows you to convert a tensor to a specified
dtype(such asuint8orbfloat16)Allows you to send a tensor to a specified
device(such ascpuorcuda)
# random pytorch tensor: float32, size=1000
tensor_fp32 = torch.rand(1000, dtype=torch.float32)
# downcast the tensor to bfloat16 using the "to" method
tensor_fp32_to_bf16 = tensor_fp32.to(dtype=torch.bfloat16)
print(f"First five elements torch.float32 {tensor_fp32[:5]}")
print(f"First five elements torch.bfloat16 {tensor_fp32_to_bf16[:5]}")
# tensor_fp32 x tensor_fp32
torch.dot(tensor_fp32, tensor_fp32)
# tensor_fp32_to_bf16 x tensor_fp32_to_bf16
torch.dot(tensor_fp32_to_bf16, tensor_fp32_to_bf16)
Downcast a Model#
We will follow an example to load Salesforce/blip-image-captioning-base from HuggingFace. It is a model that captions images
We will then inspect the model’s memory footprint in both its default float32 datatype and downcast to bfloat16.
%pip install -q transformers requests pillow
from transformers import BlipForConditionalGeneration
model_name = "Salesforce/blip-image-captioning-base"
# Download model with default dtype (float32)
model = BlipForConditionalGeneration.from_pretrained(model_name)
fp32_mem_footprint = model.get_memory_footprint()
print("Footprint of the fp32 model in MBs: ", fp32_mem_footprint / 1e6)
# Download model in bfloat16 format
model_bf16 = BlipForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.bfloat16
)
bf16_mem_footprint = model_bf16.get_memory_footprint()
print("Footprint of the bf16 model in MBs: ", bf16_mem_footprint / 1e6)
Now compare the relative size of the two formats.
# Get the relative difference of the two formats
relative_diff = bf16_mem_footprint / fp32_mem_footprint
print(f"Relative diff: {relative_diff}")
Let’s compare their performance.
# Don't worry about understanding this code
from IPython.display import display
from PIL import Image
import requests
from transformers import BlipProcessor
processor = BlipProcessor.from_pretrained(model_name)
def get_generation(model, processor, image, dtype):
inputs = processor(image, return_tensors="pt").to(dtype)
out = model.generate(**inputs)
return processor.decode(out[0], skip_special_tokens=True)
def load_image(img_url):
image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
return image
img_url = "https://storage.googleapis.com/\
sfr-vision-language-research/BLIP/demo.jpg"
image = load_image(img_url)
display(image.resize((500, 350)))
Result from original model:
results_fp32 = get_generation(model, processor, image, torch.float32)
print("fp32 Model Results:\n", results_fp32)
Result from downcast model:
results_bf16 = get_generation(model_bf16, processor, image, torch.bfloat16)
print("bf16 Model Results:\n", results_bf16)
Notice that the original model says “a woman sitting on the beach with her dog” vs. “a woman sitting on the beach with a dog.” That tiny difference in inference is the result of accumulated errors through the large number of downcast parameters throughout the model. Nothing is free!
Linear Quantization#
Quantization is the process of mapping a large set to a small set of values.

Most commonly converts float32 to int8.
Quantization can improve performance and reduce power consumption, but it may reduce accuracy.
Post-training quantization (PTQ) is performed after a model has been trained, while quantization-aware training (QAT) is performed during training.
QAT typically produces better accuracy than PTQ, but it is computationally more expensive.
Linear quantization is straightforward and effective.
Where \(r\) is the original FP32 value; \(s\) is the scale; \(q\) is the quantized INT8 value; \(z\) is the zero point.
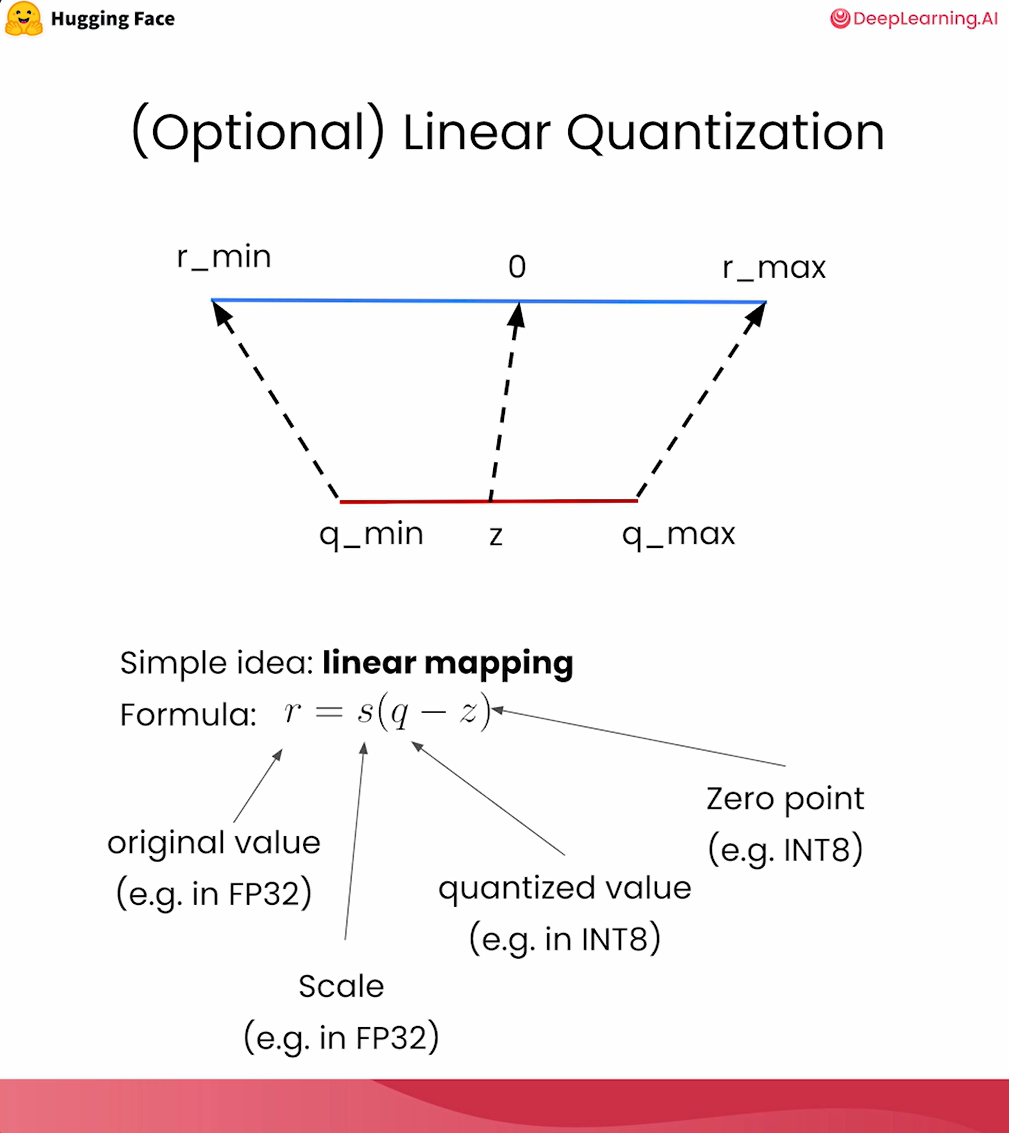
Fig. 14.1 Linear mapping from FP32 to INT8 with scale and zero point. From Quantization Fundamentals with Hugging Face#
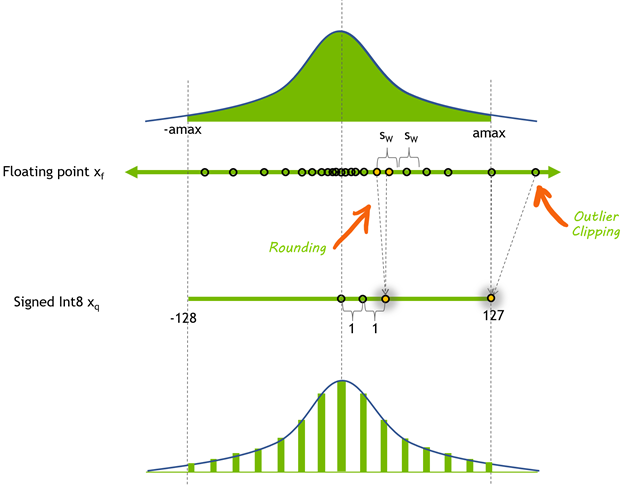
Scale and zero are found by analyzing the extreme values.
As a result, the larger the dynamic range you are trying to quantize, the poorer the precision will be!
14.4. Quantization in LiteRT#
The LiteRT 8-bit quantization specification contains more detail than what we really need. But two good things to know:
LiteRT uses signed 8-bit integer quantization according to the same formula as the one given above.
Activation functions are asymmetric, meaning the zero-point can be anywhere within the
int8range of[-128, 127]. However, model weights are symmetric, which forces the zero point equal to 0, which reduces the computational cost by eliminating a multiply.
Post-training quantization comes in several varieties.
Technique |
Benefits |
Hardware |
|---|---|---|
Dynamic range quantization |
4x smaller, 2x-3x speedup |
CPU |
Full integer quantization |
4x smaller, 3x+ speedup |
CPU, Edge TPU, Microcontrollers |
Float16 quantization |
2x smaller, GPU acceleration |
CPU, GPU |
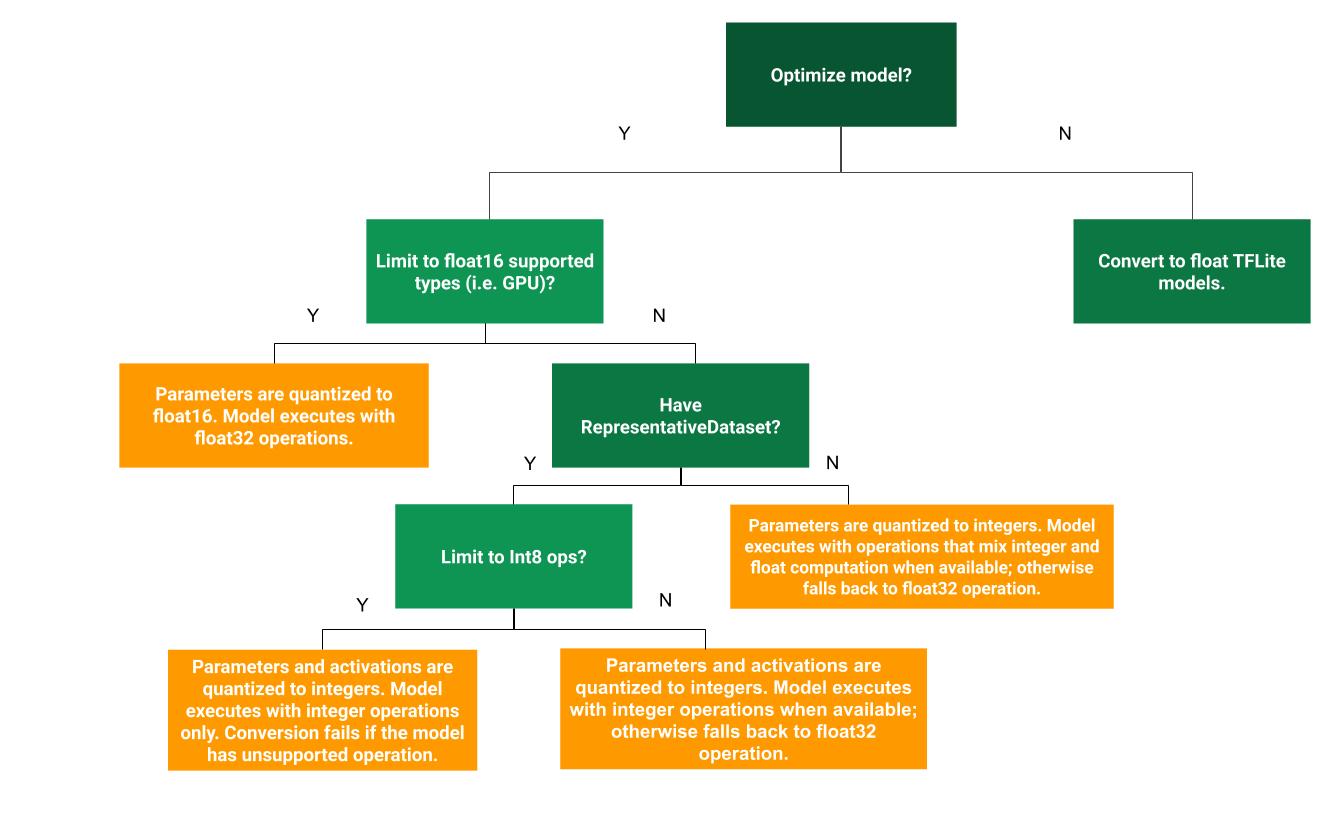
In this course we will focus on Dynamic range quantization, which is the default method when converting a TF Lite model.
Dynamic range quantization provides reduced memory usage and faster computation without you having to provide a representative dataset for calibration. This type of quantization, statically quantizes only the weights from floating point to integer at conversion time, which provides 8-bits of precision:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT] # Dynamic range quantization to int8
tflite_quant_model = converter.convert()
To further reduce latency during inference, “dynamic-range” operators dynamically quantize activations based on their range to 8-bits and perform computations with 8-bit weights and activations. This optimization provides latencies close to fully fixed-point inferences. However, the outputs are still stored using floating point so the increased speed of dynamic-range ops is less than a full fixed-point computation.
When we run inference on a Raspberry Pi, for example, we should strongly consider doing this! foreshadowing 🐱🐶