26. Text Vectorization#
The first step in Natural Language Processing (NLP) is to get the words into a format that we can do math on them.

Fig. 26.1 Tokenization of text.#
26.1. Pre-reading#
Objectives#
Gain a basic understanding of natural language processing (NLP)
Prepare text data for computer processing.
Vectorize text.
See Deep Learning with Python, 11.0 - 11.3 for lots more information.
26.2. Overview#
Natural Language Processing#
Natural language processing (NLP) is a field of computer science and a subfield of artificial intelligence that aims to make computers understand human language. NLP uses computational linguistics, which is the study of how language works, and various models based on statistics, machine learning, and deep learning. ~ Geeks for Geeks: NLP Overview
See the DeepLearning AI post for more why, what, and how.
Math with Words#
Deep learning models, being differentiable functions, can only process numeric tensors: they can’t take raw text as input. Vectorizing text is the process of transforming text into numeric tensors. ~ Deep Learning with Python, 2nd Ed
Explore the dataset to see understand what it contains.
Standardize text to make it easier to process, such as by converting it to lowercase or removing formatting.
Tokenize the text by splitting it into units.
Index the tokens into a numerical vector.
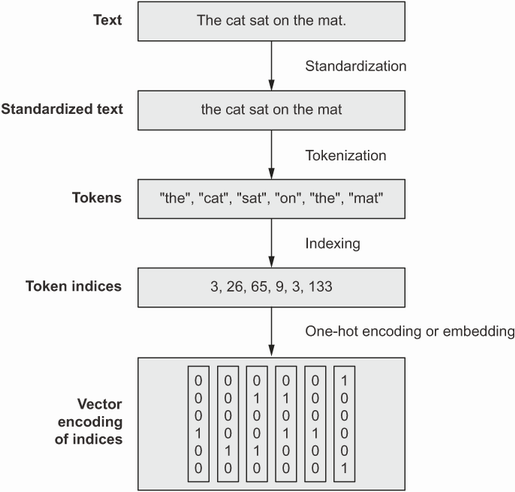
Fig. 26.2 From raw text to vectors, Deep Learning with Python, 2nd Ed, fig. 11.1#
Exploration#
Although not listed in the text book, but you should always begin with exploring the dataset to understand what it contains: data format and potential bias!
Standardization#
An example of standardization include converting to lowercase, standardizing punctuation and special characters, and stemming.
“My altitude is 7258’ above sea-level, far, far above that of West Point or Annapolis!”
“My altitude is 7258 ft. above sea level, FAR FAR above that of West point or Annapolis!”
Both should result in:
“my altitude is 7258 feet above sea level far far above that of west point or annapolis !”
Tokenization#
You can tokenize in different ways.
Here is an example of word-level tokenization.
[
"my", "altitude", "is", "7258", "feet", "above", "sea", "level", "far", "far",
"above", "that", "of", "west", "point", "or", "annapolis", "!"
]
Here is an example of bag-of-3-grams tokenization.
[
"my altitude is", "altitude is 7258", "is 7258 feet", "7258 feet above", "feet above sea",
"above sea level", "sea level far", "level far far", "far far above", "far above that",
"above that of", "that of west", "of west point", "west point or", "point or annapolis"
]
Indexing#
The simplest way to represent tokens in a vector is with the bag-of-words approach, which just counts how many times each token appears in the text.
{
"my": 1, "altitude": 1, "is": 1, "7258": 1, "feet": 1, "above": 2, "sea": 1, "level": 1,
"far": 2, "that": 1, "of": 1, "west": 1, "point": 1, "or": 1, "annapolis": 1, "!": 1
}
As simple as this is, it can be highly effective! However, you lose sequence information, which can be critical. Moving to N-grams can help!
Sequence models are a more advanced method of retaining sequence information, for more advanced use-cases.
26.3. Exercise#
For this exercise we will use Inaugural Addresses from American Presidents.
Go to the website now and think how you might put all of these into an easy-to-ingest document.
Fortunately, I”ve already extracted some of these and placed them in book/data/inagural_addresses.csv
# Download the dataset, if not running in VSCode
# !wget https://raw.githubusercontent.com/USAFA-ECE/ece386-book/refs/heads/main/book/data/inaugural_addresses.csv
As always, we should preview some stats about what we are diving in to.
import pandas as pd
# Change if running in colab
csv_path = "../data/inaugural_addresses.csv"
# Load the CSV into a pandas DataFrame
df = pd.read_csv(csv_path)
# Display the first few rows of the DataFrame and its summary
df_head = df.head()
df_info = df.info()
df_head
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 President 6 non-null object
1 Year 6 non-null int64
2 Text 6 non-null object
dtypes: int64(1), object(2)
memory usage: 272.0+ bytes
| President | Year | Text | |
|---|---|---|---|
| 0 | Biden | 2021 | Chief Justice Roberts, Vice President Harris, ... |
| 1 | Trump | 2017 | Chief Justice Roberts, President Carter, Presi... |
| 2 | Obama | 2013 | Thank you. Thank you so much. Vice President ... |
| 3 | Obama | 2009 | My fellow citizens, I stand here today humbled... |
| 4 | Bush | 2005 | Vice President Cheney, Mr. Chief Justice, Pres... |
Word Clouds#
Unlike numerical data, we cannot easily do things like mean, median, or standard deviation with text data.
Let’s try a word cloud, just for fun.
%pip install -q wordcloud
Note: you may need to restart the kernel to use updated packages.
import matplotlib.pyplot as plt
from wordcloud import WordCloud
def plot_wordcloud(df: pd.DataFrame, column: str = "Text") -> None:
# Set up the figure size and number of subplots
fig, axes = plt.subplots(nrows=df.shape[0], ncols=1, figsize=(15, 30))
# Loop through each row of the DataFrame and generate a word cloud from the column
for i, (index, row) in enumerate(df.iterrows()):
# Create a word cloud object
wc = WordCloud(
# stopwords is empty here, but can replace with wordcloud.STOPWORDS as a default list
background_color="white",
stopwords=[],
max_words=100,
width=800,
height=400,
)
# Generate the word cloud from the column variable
wc.generate(row[column])
# Display the word cloud on the subplot
axes[i].imshow(wc, interpolation="bilinear")
axes[i].axis("off")
axes[i].set_title(f"{row['President']} ({row['Year']})", fontsize=37)
plot_wordcloud(df)

26.4. Standardize#
We will do the following to standardize our dataset:
Convert to lowercase
Remove stop words
Apply stemming
Stop Words#
As you can see in word clouds, words such as “and” and “the” dominate, but don”t provide very much meaning.
To combat this, we will be Removing stop words with NLTK in Python.
Note
By default the WordCloud class applies english stop words present in the wordcloud.STOPWORDS list.
The code above deliberately prevented this by passing the argument stopwords=[].
%pip install -q nltk
Note: you may need to restart the kernel to use updated packages.
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
print(stopwords.words("english"))
['a', 'about', 'above', 'after', 'again', 'against', 'ain', 'all', 'am', 'an', 'and', 'any', 'are', 'aren', "aren't", 'as', 'at', 'be', 'because', 'been', 'before', 'being', 'below', 'between', 'both', 'but', 'by', 'can', 'couldn', "couldn't", 'd', 'did', 'didn', "didn't", 'do', 'does', 'doesn', "doesn't", 'doing', 'don', "don't", 'down', 'during', 'each', 'few', 'for', 'from', 'further', 'had', 'hadn', "hadn't", 'has', 'hasn', "hasn't", 'have', 'haven', "haven't", 'having', 'he', "he'd", "he'll", 'her', 'here', 'hers', 'herself', "he's", 'him', 'himself', 'his', 'how', 'i', "i'd", 'if', "i'll", "i'm", 'in', 'into', 'is', 'isn', "isn't", 'it', "it'd", "it'll", "it's", 'its', 'itself', "i've", 'just', 'll', 'm', 'ma', 'me', 'mightn', "mightn't", 'more', 'most', 'mustn', "mustn't", 'my', 'myself', 'needn', "needn't", 'no', 'nor', 'not', 'now', 'o', 'of', 'off', 'on', 'once', 'only', 'or', 'other', 'our', 'ours', 'ourselves', 'out', 'over', 'own', 're', 's', 'same', 'shan', "shan't", 'she', "she'd", "she'll", "she's", 'should', 'shouldn', "shouldn't", "should've", 'so', 'some', 'such', 't', 'than', 'that', "that'll", 'the', 'their', 'theirs', 'them', 'themselves', 'then', 'there', 'these', 'they', "they'd", "they'll", "they're", "they've", 'this', 'those', 'through', 'to', 'too', 'under', 'until', 'up', 've', 'very', 'was', 'wasn', "wasn't", 'we', "we'd", "we'll", "we're", 'were', 'weren', "weren't", "we've", 'what', 'when', 'where', 'which', 'while', 'who', 'whom', 'why', 'will', 'with', 'won', "won't", 'wouldn', "wouldn't", 'y', 'you', "you'd", "you'll", 'your', "you're", 'yours', 'yourself', 'yourselves', "you've"]
[nltk_data] Downloading package stopwords to /home/bcy/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
Stemming#
Stemming reduces an inflected word to its base; for example: runs; running; ran –> “run”.
from nltk.stem import PorterStemmer
# create an object of class PorterStemmer
porter = PorterStemmer()
print(porter.stem("play"))
print(porter.stem("playing"))
print(porter.stem("plays"))
print(porter.stem("played"))
play
play
play
play
Lemmatization#
Another common text pre-processing technique is lemmatization.
In linguistics, is the process of grouping together the inflected forms of a word so they can be analyzed as a single item, identified by the word”s lemma, or dictionary form.
Stemming reduces an inflected word to its base; for example: runs; running; ran –> “run”.
Lemmatizing goes further by using knowledge of surrounding words.
The word “better” has “good” as its lemma. This link is missed by stemming, as it requires a dictionary look-up.
The word “walk” is the base form for the word “walking”, and hence this is matched in both stemming and lemmatization.
The word “meeting” can be either the base form of a noun or a form of a verb (“to meet”) depending on the context; e.g., “in our last meeting” or “We are meeting again tomorrow”. Unlike stemming, lemmatization attempts to select the correct lemma depending on the context.
26.5. Tokenize#
Because of how nltk works, we will actually standardize while we tokenize. In our case, we will just do word tokens, but there are many other options!
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
# Download a pre-trained tokenizer
# https://www.nltk.org/api/nltk.tokenize.punkt.html
nltk.download("punkt_tab")
# Reload df so it's fresh
df = pd.read_csv(csv_path)
# Presidents say America a lot, so add that to the stopwords
stopword_list = stopwords.words("english")
stopword_list.append("america")
# Initialize the stemmer
stemmer = PorterStemmer()
# Define a function that applies stemming and stopwords removal
def preprocess(text):
# Tokenize the text word-by-word
tokens = nltk.word_tokenize(text)
# Convert to lowercase, remove stopwords, and apply stemming
tokens = [
stemmer.stem(word) for word in tokens if word.lower() not in stopword_list
]
return tokens
# Apply the function to the "text" column
df["tokens"] = df["Text"].apply(preprocess)
# Preview the result
print(f"Original text: \n{df['Text'].head()}")
print(f"Tokens: \n{df['tokens'].head()}")
[nltk_data] Downloading package punkt_tab to /home/bcy/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
Original text:
0 Chief Justice Roberts, Vice President Harris, ...
1 Chief Justice Roberts, President Carter, Presi...
2 Thank you. Thank you so much. Vice President ...
3 My fellow citizens, I stand here today humbled...
4 Vice President Cheney, Mr. Chief Justice, Pres...
Name: Text, dtype: object
Tokens:
0 [chief, justic, robert, ,, vice, presid, harri...
1 [chief, justic, robert, ,, presid, carter, ,, ...
2 [thank, ., thank, much, ., vice, presid, biden...
3 [fellow, citizen, ,, stand, today, humbl, task...
4 [vice, presid, cheney, ,, mr., chief, justic, ...
Name: tokens, dtype: object
# Put clean text back into a string for wordcloud
df["standardized_text"] = df["tokens"].apply(lambda x: " ".join(x))
plot_wordcloud(df, "standardized_text")

26.6. Index#
Now we get to put our standardized words into a vector!
We will be using scikit-learn”s CountVectorizer to Extracting Features from Text (Geeks for Geeks).
Class
CountVectorizerconverts a collection of text documents to a matrix of token counts. This implementation produces a sparse representation of the counts using scipy.sparse.csr_matrix.
Bag of Words#
The naive - but sometimes highly effective - approach is the “Bag of Words” approach: simply count how many times words show up!
This is actually what are word clouds are doing under the hood!
Important
This produces a sparse matrix, meaning there are lots of zeros! As a pro, such matrices can be highly compressed. However, they also present unique challenges in machine learning.
from sklearn.feature_extraction.text import CountVectorizer
# Create a Vectorizer Object
vectorizer = CountVectorizer()
document = df["standardized_text"]
vectorizer.fit(document)
# Printing the identified Unique words along with their indices
print("Vocabulary: ", vectorizer.vocabulary_)
# Encode the Document
vector = vectorizer.transform(document)
# Summarizing the Encoded Texts
print("Encoded Document is:")
print(vector.toarray())
Vocabulary: {'chief': 232, 'justic': 820, 'robert': 1280, 'vice': 1631, 'presid': 1136, 'harri': 693, 'speaker': 1415, 'pelosi': 1077, 'leader': 848, 'schumer': 1315, 'mcconnel': 918, 'penc': 1079, 'distinguish': 425, 'guest': 675, 'fellow': 564, 'american': 61, 'day': 349, 'democraci': 380, 'histori': 720, 'hope': 728, 'renew': 1236, 'resolv': 1249, 'crucibl': 335, 'age': 36, 'test': 1520, 'anew': 70, 'risen': 1275, 'challeng': 221, 'today': 1543, 'celebr': 212, 'triumph': 1571, 'candid': 195, 'caus': 209, 'people': 1081, 'th': 1521, 'peopl': 1080, 'heard': 701, 'heed': 704, 've': 1628, 'learn': 850, 'preciou': 1124, 'fragil': 613, 'hour': 732, 'friend': 617, 'prevail': 1141, 'hallow': 680, 'ground': 666, 'ago': 39, 'violenc': 1638, 'sought': 1406, 'shake': 1347, 'capitol': 199, 'foundat': 610, 'come': 266, 'togeth': 1544, 'one': 1023, 'nation': 981, 'god': 646, 'indivis': 772, 'carri': 204, 'peac': 1073, 'transfer': 1559, 'power': 1121, 'two': 1581, 'centuri': 216, 'look': 886, 'ahead': 41, 'uniqu': 1600, 'way': 1661, 'restless': 1256, 'bold': 162, 'optimistic': 1031, 'and': 69, 'set': 1343, 'sight': 1367, 'know': 829, 'must': 974, 'thank': 1522, 'predecessor': 1126, 'parti': 1058, 'presenc': 1133, 'bottom': 166, 'heart': 702, 'resili': 1247, 'constitut': 304, 'strength': 1457, 'carter': 205, 'spoke': 1425, 'last': 843, 'night': 998, 'us': 1623, 'salut': 1303, 'lifetim': 869, 'servic': 1341, 'taken': 1502, 'sacr': 1294, 'oath': 1009, 'patriot': 1070, 'first': 577, 'sworn': 1496, 'georg': 632, 'washington': 1655, 'stori': 1452, 'depend': 384, 'seek': 1325, 'perfect': 1083, 'union': 1599, 'great': 659, 'good': 648, 'storm': 1453, 'strife': 1459, 'war': 1653, 'far': 554, 'still': 1445, 'go': 644, 'll': 882, 'press': 1138, 'forward': 607, 'speed': 1420, 'urgenc': 1621, 'much': 968, 'winter': 1693, 'peril': 1085, 'signific': 1369, 'possibl': 1116, 'repair': 1237, 'restor': 1257, 'heal': 698, 'build': 182, 'gain': 625, 'found': 609, 'time': 1538, 'difficult': 403, 're': 1192, 'once': 1022, 'in': 762, 'viru': 1641, 'silent': 1371, 'stalk': 1432, 'countri': 319, 'mani': 903, 'live': 881, 'year': 1720, 'lost': 889, 'world': 1707, 'ii': 751, 'million': 941, 'job': 811, 'hundr': 740, 'thousand': 1531, 'busi': 187, 'close': 258, 'cri': 327, 'racial': 1180, '400': 10, 'make': 898, 'move': 965, 'dream': 442, 'defer': 373, 'longer': 885, 'surviv': 1486, 'planet': 1102, 'ca': 189, 'desper': 392, 'clear': 252, 'rise': 1274, 'polit': 1112, 'extrem': 535, 'white': 1683, 'supremaci': 1481, 'domest': 436, 'terror': 1519, 'confront': 293, 'defeat': 370, 'overcom': 1045, 'challenges': 222, 'to': 1542, 'soul': 1407, 'secur': 1322, 'futur': 624, 'america': 60, 'requir': 1243, 'word': 1703, 'elus': 469, 'thing': 1526, 'uniti': 1602, 'anoth': 73, 'januari': 807, 'new': 994, '1863': 4, 'abraham': 14, 'lincoln': 875, 'sign': 1368, 'emancip': 471, 'proclam': 1154, 'put': 1174, 'pen': 1078, 'paper': 1055, 'said': 1300, 'quot': 1178, 'name': 979, 'ever': 510, 'goe': 647, 'act': 24, 'whole': 1684, 'bring': 174, 'unit': 1601, 'ask': 97, 'everi': 511, 'join': 814, 'fight': 569, 'foe': 587, 'face': 537, 'anger': 72, 'resent': 1245, 'hatr': 695, 'lawless': 845, 'diseas': 417, 'jobless': 812, 'hopeless': 729, 'import': 759, 'right': 1270, 'wrong': 1717, 'work': 1704, 'teach': 1510, 'children': 235, 'safe': 1298, 'school': 1314, 'deadli': 351, 'reward': 1267, 'rebuild': 1202, 'middl': 935, 'class': 250, 'health': 699, 'care': 202, 'deliv': 378, 'lead': 847, 'forc': 593, 'speak': 1414, 'sound': 1408, 'like': 872, 'foolish': 590, 'fantasi': 553, 'divid': 429, 'deep': 367, 'real': 1197, 'also': 56, 'constant': 302, 'struggl': 1463, 'ideal': 747, 'creat': 323, 'equal': 499, 'harsh': 694, 'ugli': 1584, 'realiti': 1198, 'racism': 1181, 'nativ': 982, 'fear': 561, 'demon': 382, 'long': 884, 'torn': 1551, 'apart': 79, 'battl': 119, 'perenni': 1082, 'victori': 1633, 'never': 993, 'assur': 100, 'civil': 247, 'depress': 386, '11': 2, 'sacrific': 1296, 'setback': 1344, 'better': 141, 'angel': 71, 'alway': 57, 'moment': 953, 'enough': 492, 'hav': 696, 'faith': 545, 'reason': 1201, 'show': 1361, 'see': 1323, 'adversari': 29, 'neighbor': 990, 'treat': 1565, 'digniti': 407, 'respect': 1251, 'stop': 1451, 'shout': 1360, 'lower': 892, 'temperatur': 1515, 'without': 1698, 'bitter': 152, 'furi': 623, 'progress': 1159, 'exhaust': 524, 'outrag': 1042, 'state': 1439, 'chao': 225, 'histor': 719, 'crisi': 331, 'path': 1068, 'meet': 924, 'guarante': 672, 'fail': 541, 'place': 1099, 'let': 862, 'start': 1437, 'afresh': 34, 'begin': 128, 'listen': 877, 'hear': 700, 'rage': 1183, 'fire': 574, 'destroy': 394, 'everyth': 513, 'disagr': 412, 'total': 1552, 'reject': 1226, 'cultur': 336, 'fact': 538, 'manipul': 904, 'even': 507, 'manufactur': 906, 'differ': 402, 'believ': 133, 'around': 91, 'stand': 1433, 'shadow': 1346, 'dome': 435, 'mention': 928, 'earlier': 452, 'complet': 281, 'amid': 63, 'liter': 879, 'hang': 683, 'balanc': 113, 'yet': 1722, 'endur': 483, 'mall': 900, 'dr': 439, 'king': 827, '108': 1, 'inaugur': 764, 'protest': 1166, 'tri': 1568, 'block': 158, 'brave': 169, 'women': 1701, 'march': 907, 'vote': 1646, 'mark': 909, 'swearing': 1489, 'woman': 1700, 'elect': 466, 'offic': 1019, 'kamala': 821, 'tell': 1513, 'chang': 224, 'across': 23, 'potomac': 1119, 'arlington': 88, 'cemeteri': 213, 'hero': 710, 'gave': 628, 'full': 622, 'measur': 921, 'devot': 399, 'rest': 1254, 'etern': 506, 'riotou': 1272, 'mob': 950, 'thought': 1530, 'could': 317, 'use': 1624, 'silenc': 1370, 'drive': 444, 'happen': 684, 'tomorrow': 1550, 'not': 1003, 'support': 1480, 'campaign': 193, 'humbl': 737, 'say': 1309, 'take': 1501, 'disagre': 413, 'dissent': 420, 'peaceabl': 1074, 'within': 1697, 'guardrail': 674, 'republ': 1242, 'perhap': 1084, 'greatest': 661, 'clearli': 253, 'disunion': 427, 'pledg': 1107, 'americans': 62, 'al': 45, 'promis': 1161, 'hard': 687, 'saint': 1301, 'augustin': 103, 'church': 240, 'wrote': 1718, 'multitud': 970, 'defin': 375, 'common': 272, 'object': 1011, 'love': 891, 'think': 1527, 'opportun': 1027, 'liberti': 866, 'honor': 727, 'ye': 1719, 'truth': 1576, 'recent': 1204, 'week': 1668, 'month': 955, 'taught': 1508, 'pain': 1053, 'lesson': 860, 'lie': 867, 'told': 1547, 'profit': 1156, 'duti': 451, 'respons': 1253, 'citizen': 243, 'especi': 503, 'leaders': 849, 'protect': 1165, 'defend': 371, 'understand': 1592, 'view': 1634, 'trepid': 1567, 'worri': 1710, 'dad': 343, 'lay': 846, 'bed': 125, 'stare': 1436, 'ceil': 211, 'wonder': 1702, 'keep': 822, 'pay': 1072, 'mortgag': 959, 'famili': 552, 'next': 997, 'get': 633, 'answer': 74, 'turn': 1579, 'inward': 800, 'retreat': 1261, 'compet': 278, 'faction': 539, 'distrust': 426, 'worship': 1711, 'news': 995, 'sourc': 1409, 'end': 480, 'uncivil': 1588, 'pit': 1098, 'red': 1212, 'blue': 160, 'rural': 1291, 'versu': 1630, 'urban': 1620, 'conserv': 299, 'liber': 865, 'open': 1025, 'instead': 789, 'harden': 688, 'littl': 880, 'toler': 1548, 'humil': 738, 'will': 1688, 'person': 1092, 'shoe': 1355, 'mom': 952, 'would': 1714, 'life': 868, 'account': 20, 'fate': 557, 'deal': 353, 'need': 989, 'hand': 682, 'call': 191, 'lend': 857, 'stronger': 1462, 'prosper': 1164, 'readi': 1195, 'persever': 1090, 'dark': 345, 'enter': 495, 'may': 917, 'toughest': 1554, 'deadliest': 352, 'period': 1086, 'asid': 96, 'final': 571, 'pandem': 1054, 'bibl': 143, 'weep': 1669, 'joy': 816, 'cometh': 267, 'morn': 957, 'together': 1545, 'folk': 588, 'colleagu': 262, 'serv': 1339, 'hous': 733, 'senat': 1333, 'watch': 1656, 'messag': 932, 'beyond': 142, 'border': 164, 'allianc': 49, 'engag': 487, 'yesterday': 1721, 'mere': 931, 'exampl': 518, 'strong': 1461, 'trust': 1575, 'partner': 1061, 'prayer': 1122, 'rememb': 1233, 'past': 1064, '000': 0, 'husband': 744, 'wive': 1699, 'son': 1403, 'daughter': 348, 'cowork': 322, 'becom': 124, 'left': 854, 'behind': 131, 'point': 1110, 'observ': 1014, 'amen': 59, 'attack': 101, 'grow': 668, 'inequ': 775, 'sting': 1446, 'system': 1498, 'climat': 255, 'role': 1282, 'profound': 1157, 'present': 1134, 'gravest': 658, 'step': 1444, 'certain': 219, 'judg': 817, 'cascad': 206, 'crise': 330, 'era': 501, 'occas': 1015, 'question': 1176, 'master': 912, 'rare': 1188, 'oblig': 1012, 'pass': 1062, 'along': 53, 'sure': 1482, 'well': 1672, 'write': 1716, 'chapter': 226, 'might': 937, 'someth': 1401, 'song': 1404, 'mean': 919, 'lot': 890, 'anthem': 75, 'vers': 1629, 'least': 851, 'brought': 180, 'shall': 1348, 'legaci': 855, 'best': 138, 'add': 26, 'unfold': 1596, 'broken': 178, 'land': 836, 'began': 127, 'give': 638, 'level': 864, 'you': 1724, 'interest': 796, 'public': 1170, 'divis': 430, 'light': 871, 'decenc': 359, 'guid': 676, 'inspir': 788, 'met': 933, 'die': 401, 'thrive': 1534, 'home': 722, 'stood': 1450, 'beacon': 120, 'owe': 1048, 'forebear': 594, 'gener': 630, 'follow': 589, 'purpos': 1171, 'task': 1506, 'sustain': 1488, 'driven': 445, 'convict': 311, 'bless': 157, 'troop': 1572, 'clinton': 257, 'bush': 186, 'obama': 1010, 'effort': 465, 'determin': 396, 'cours': 321, 'hardship': 691, 'done': 437, 'gather': 627, 'orderli': 1034, 'grate': 656, 'ladi': 835, 'michel': 934, 'graciou': 652, 'aid': 42, 'throughout': 1535, 'transit': 1561, 'magnific': 896, 'ceremoni': 218, 'howev': 734, 'special': 1416, 'administr': 27, 'dc': 350, 'back': 108, 'small': 1389, 'group': 667, 'capit': 198, 'reap': 1200, 'govern': 650, 'born': 165, 'cost': 315, 'flourish': 584, 'share': 1350, 'wealth': 1664, 'politician': 1113, 'factori': 540, 'establish': 505, 'belong': 135, 'everyon': 512, 'truli': 1574, 'matter': 916, 'control': 310, 'whether': 1679, '20': 5, '2017': 7, 'becam': 123, 'ruler': 1289, 'forgotten': 601, 'men': 927, 'came': 192, 'ten': 1516, 'part': 1057, 'movement': 966, 'seen': 1327, 'center': 214, 'crucial': 334, 'exist': 526, 'want': 1652, 'neighborhood': 991, 'demand': 379, 'righteou': 1271, 'mother': 961, 'trap': 1562, 'poverti': 1120, 'inner': 784, 'citi': 242, 'rusted': 1292, 'out': 1038, 'scatter': 1313, 'tombston': 1549, 'landscap': 837, 'educ': 463, 'flush': 586, 'cash': 207, 'leav': 852, 'young': 1725, 'beauti': 122, 'student': 1464, 'depriv': 387, 'knowledg': 830, 'crime': 328, 'gang': 626, 'drug': 447, 'stolen': 1448, 'rob': 1279, 'unreal': 1609, 'potenti': 1118, 'carnag': 203, 'success': 1472, 'gloriou': 643, 'destini': 393, 'allegi': 47, 'decad': 356, 'enrich': 493, 'foreign': 595, 'industri': 774, 'expens': 532, 'subsid': 1468, 'armi': 90, 'allow': 50, 'sad': 1297, 'deplet': 385, 'militari': 938, 'refus': 1218, 'spent': 1422, 'trillion': 1570, 'dollar': 434, 'oversea': 1046, 'infrastructur': 780, 'fallen': 547, 'disrepair': 419, 'decay': 357, 'made': 895, 'rich': 1268, 'confid': 291, 'dissip': 422, 'horizon': 730, 'shutter': 1364, 'shore': 1356, 'worker': 1705, 'rip': 1273, 'redistribut': 1214, 'assembl': 99, 'issu': 804, 'decre': 365, 'hall': 679, 'vision': 1643, 'decis': 362, 'trade': 1556, 'tax': 1509, 'immigr': 755, 'affair': 30, 'benefit': 137, 'ravag': 1190, 'product': 1155, 'steal': 1442, 'compani': 274, 'breath': 171, 'bodi': 161, 'win': 1690, 'road': 1278, 'highway': 715, 'bridg': 172, 'airport': 44, 'tunnel': 1578, 'railway': 1185, 'welfar': 1671, 'labor': 834, 'simpl': 1373, 'rule': 1288, 'buy': 188, 'hire': 718, 'friendship': 619, 'impos': 761, 'anyon': 77, 'rather': 1189, 'shine': 1353, 'example': 519, 'for': 592, 'reinforc': 1224, 'old': 1021, 'form': 602, 'radic': 1182, 'islam': 803, 'erad': 502, 'earth': 454, 'bedrock': 126, 'loyalti': 893, 'rediscov': 1213, 'room': 1284, 'prejudic': 1128, 'pleasant': 1105, 'mind': 942, 'openli': 1026, 'debat': 355, 'honestli': 726, 'pursu': 1172, 'solidar': 1399, 'unstopp': 1610, 'law': 844, 'enforc': 486, 'importantli': 760, 'big': 145, 'bigger': 146, 'strive': 1460, 'accept': 18, 'talk': 1504, 'action': 25, 'constantli': 303, 'complain': 280, 'anyth': 78, 'empti': 476, 'arriv': 92, 'match': 913, 'spirit': 1424, 'birth': 150, 'millennium': 940, 'unlock': 1606, 'mysteri': 976, 'space': 1411, 'free': 615, 'miseri': 944, 'har': 686, 'energi': 485, 'technolog': 1512, 'pride': 1144, 'stir': 1447, 'lift': 870, 'wisdom': 1694, 'soldier': 1397, 'forget': 599, 'black': 153, 'brown': 181, 'bleed': 156, 'blood': 159, 'enjoy': 489, 'freedom': 616, 'flag': 581, 'child': 233, 'sprawl': 1427, 'detroit': 397, 'windswept': 1692, 'plain': 1100, 'nebraska': 986, 'sky': 1383, 'fill': 570, 'infus': 781, 'almighti': 51, 'creator': 324, 'near': 984, 'larg': 840, 'mountain': 964, 'ocean': 1016, 'ignor': 750, 'voic': 1645, 'courag': 320, 'forev': 597, 'wealthi': 1665, 'proud': 1167, 'biden': 144, 'mr': 967, 'member': 925, 'congress': 294, 'bear': 121, 'wit': 1696, 'affirm': 31, 'recal': 1203, 'bind': 149, 'color': 265, 'skin': 1382, 'tenet': 1517, 'origin': 1035, 'exceptional': 520, 'what': 1675, 'idea': 746, 'articul': 94, 'declar': 363, 'hold': 721, 'self': 1330, 'evid': 515, 'endow': 482, 'unalien': 1586, 'among': 65, 'pursuit': 1173, 'happi': 685, 'continu': 308, 'journey': 815, 'execut': 522, 'gift': 636, '1776': 3, 'replac': 1238, 'tyranni': 1582, 'privileg': 1151, 'entrust': 498, 'creed': 326, '200': 6, 'drawn': 441, 'lash': 842, 'sword': 1495, 'principl': 1147, 'half': 678, 'slav': 1385, 'fre': 614, 'vow': 1647, 'modern': 951, 'economi': 460, 'railroad': 1184, 'travel': 1563, 'commerc': 270, 'colleg': 264, 'train': 1558, 'discov': 416, 'market': 910, 'ensur': 494, 'competit': 279, 'fair': 544, 'play': 1103, 'vulner': 1648, 'worst': 1712, 'hazard': 697, 'misfortun': 945, 'relinquish': 1230, 'skeptic': 1380, 'central': 215, 'author': 104, 'succumb': 1473, 'fiction': 567, 'societi': 1395, 'ill': 752, 'cure': 337, 'alon': 52, 'initi': 783, 'enterpris': 496, 'insist': 787, 'charact': 227, 'understood': 1593, 'fidel': 568, 'preserv': 1135, 'individu': 771, 'ultim': 1585, 'collect': 263, 'fascism': 556, 'commun': 273, 'musket': 972, 'militia': 939, 'singl': 1377, 'math': 915, 'scienc': 1316, 'teacher': 1511, 'equip': 500, 'network': 992, 'research': 1244, 'lab': 833, 'steel': 1443, 'prove': 1168, 'econom': 459, 'recoveri': 1210, 'begun': 129, 'limitless': 874, 'possess': 1115, 'qualiti': 1175, 'boundari': 168, 'youth': 1727, 'divers': 428, 'endless': 481, 'capac': 197, 'risk': 1276, 'reinvent': 1225, 'seiz': 1329, 'it': 805, 'so': 1393, 'succeed': 1471, 'shrink': 1363, 'bare': 116, 'upon': 1619, 'broad': 176, 'shoulder': 1359, 'find': 572, 'independ': 768, 'wage': 1649, 'honest': 724, 'brink': 175, 'true': 1573, 'girl': 637, 'bleakest': 155, 'chanc': 223, 'anybodi': 76, 'els': 468, 'eye': 536, 'outworn': 1044, 'program': 1158, 'inadequ': 763, 'remak': 1232, 'revamp': 1263, 'code': 260, 'reform': 1217, 'empow': 475, 'skill': 1381, 'harder': 689, 'reach': 1193, 'higher': 713, 'deserv': 391, 'basic': 118, 'choic': 236, 'reduc': 1215, 'size': 1379, 'deficit': 374, 'belief': 132, 'choos': 237, 'built': 183, 'invest': 798, 'twilight': 1580, 'parent': 1056, 'disabl': 411, 'nowher': 1006, 'reserv': 1246, 'lucki': 894, 'recogn': 1207, 'loss': 888, 'sudden': 1474, 'swept': 1491, 'away': 106, 'terribl': 1518, 'commit': 271, 'medicar': 923, 'medicaid': 922, 'social': 1394, 'sap': 1305, 'strengthen': 1458, 'taker': 1503, 'poster': 1117, 'respond': 1252, 'threat': 1532, 'failur': 542, 'betray': 140, 'deni': 383, 'overwhelm': 1047, 'judgment': 818, 'none': 1001, 'avoid': 105, 'devast': 398, 'impact': 756, 'crippl': 329, 'drought': 446, 'toward': 1555, 'sometim': 1402, 'resist': 1248, 'cede': 210, 'claim': 248, 'maintain': 897, 'vital': 1644, 'treasure': 1564, 'our': 1037, 'forest': 596, 'waterway': 1658, 'crop': 332, 'snow': 1392, 'cap': 196, 'peak': 1076, 'command': 269, 'father': 558, 'perpetu': 1089, 'uniform': 1598, 'temper': 1514, 'flame': 582, 'unmatch': 1607, 'sear': 1319, 'memori': 926, 'price': 1143, 'paid': 1052, 'vigil': 1636, 'harm': 692, 'heir': 705, 'enemi': 484, 'surest': 1483, 'friends': 618, 'uphold': 1618, 'valu': 1626, 'arm': 89, 'peacefully': 1075, 'naiv': 978, 'danger': 344, 'durabl': 448, 'suspicion': 1487, 'remain': 1231, 'anchor': 67, 'corner': 313, 'globe': 642, 'institut': 790, 'extend': 534, 'manag': 902, 'abroad': 15, 'greater': 660, 'stake': 1430, 'asia': 95, 'africa': 35, 'east': 457, 'conscienc': 296, 'compel': 277, 'behalf': 130, 'poor': 1114, 'sick': 1365, 'margin': 908, 'victim': 1632, 'prejudice': 1129, 'chariti': 228, 'advanc': 28, 'describ': 389, 'human': 736, 'truths': 1577, 'that': 1523, 'star': 1435, 'seneca': 1334, 'fall': 546, 'selma': 1332, 'stonewal': 1449, 'sung': 1479, 'unsung': 1611, 'footprint': 591, 'preacher': 1123, 'walk': 1651, 'proclaim': 1153, 'inextric': 778, 'bound': 167, 'pioneer': 1097, 'earn': 453, 'gay': 629, 'brother': 179, 'sister': 1378, 'wait': 1650, 'exercis': 523, 'welcom': 1670, 'opportunity': 1028, 'until': 1613, 'bright': 173, 'engin': 488, 'enlist': 490, 'workforc': 1706, 'expel': 531, 'street': 1456, 'hill': 716, 'appalachia': 82, 'quiet': 1177, 'lane': 838, 'newtown': 996, 'cherish': 231, 'document': 431, 'agre': 40, 'contour': 309, 'exactli': 517, 'precis': 1125, 'settl': 1345, 'centuries': 217, 'afford': 32, 'delay': 377, 'mistak': 949, 'absolut': 16, 'substitut': 1470, 'spectacl': 1417, 'cal': 190, 'imperfect': 758, 'partial': 1059, '40': 9, 'henc': 708, 'timeless': 1539, 'confer': 290, 'spare': 1413, 'philadelphia': 1095, 'recit': 1205, 'other': 1036, 'durat': 449, 'realiz': 1199, 'wave': 1659, 'repres': 1240, 'shape': 1349, 'cast': 208, 'defens': 372, 'ancient': 68, 'embrac': 473, 'solemn': 1398, 'awesom': 107, 'birthright': 151, 'passion': 1063, 'dedic': 366, 'uncertain': 1587, 'bestow': 139, 'ancestor': 66, 'generos': 631, 'cooper': 312, 'shown': 1362, 'forty': 606, 'four': 612, 'presidenti': 1137, 'spoken': 1426, 'tide': 1536, 'water': 1657, 'often': 1020, 'amidst': 64, 'cloud': 259, 'simpli': 1374, 'high': 712, 'midst': 936, 'badli': 111, 'weaken': 1663, 'consequ': 297, 'greed': 662, 'irrespons': 802, 'prepar': 1131, 'shed': 1351, 'costli': 316, 'threaten': 1533, 'indic': 769, 'subject': 1467, 'data': 347, 'statist': 1441, 'less': 858, 'nag': 977, 'declin': 364, 'inevit': 776, 'seriou': 1337, 'easili': 456, 'short': 1357, 'span': 1412, 'chosen': 238, 'conflict': 292, 'discord': 415, 'petti': 1094, 'grievanc': 664, 'fals': 549, 'recrimin': 1211, 'worn': 1709, 'dogma': 433, 'strangl': 1455, 'scriptur': 1317, 'childish': 234, 'reaffirm': 1196, 'nobl': 999, 'given': 639, 'shortcut': 1358, 'faintheart': 543, 'prefer': 1127, 'leisur': 856, 'pleasur': 1106, 'fame': 551, 'tak': 1500, 'doer': 432, 'maker': 899, 'obscur': 1013, 'rug': 1287, 'pack': 1050, 'worldli': 1708, 'search': 1320, 'toil': 1546, 'sweatshop': 1490, 'west': 1674, 'whip': 1680, 'plow': 1109, 'fought': 608, 'concord': 287, 'gettysburg': 634, 'normandi': 1002, 'khe': 824, 'sanh': 1304, 'sacrif': 1295, 'til': 1537, 'raw': 1191, 'saw': 1308, 'sum': 1477, 'ambit': 58, 'invent': 797, 'undiminish': 1594, 'pat': 1066, 'narrow': 980, 'unpleas': 1608, 'pick': 1096, 'dust': 450, 'everywher': 514, 'swift': 1492, 'growth': 669, 'electr': 467, 'grid': 663, 'digit': 405, 'line': 876, 'feed': 562, 'wield': 1687, 'rais': 1186, 'sun': 1478, 'wind': 1691, 'soil': 1396, 'fuel': 620, 'car': 201, 'run': 1290, 'transform': 1560, 'univers': 1603, 'scale': 1310, 'suggest': 1476, 'plan': 1101, 'alreadi': 55, 'achiev': 22, 'imagin': 754, 'necess': 987, 'cynic': 342, 'shift': 1352, 'beneath': 136, 'stale': 1431, 'argument': 86, 'consum': 305, 'appli': 85, 'help': 707, 'decent': 360, 'retir': 1260, 'dignifi': 406, 'intend': 795, 'held': 706, 'spend': 1421, 'wise': 1695, 'bad': 110, 'habit': 677, 'expand': 527, 'remind': 1235, 'spin': 1423, 'favor': 560, 'gross': 665, 'abil': 13, 'rout': 1286, 'safeti': 1299, 'scarc': 1312, 'draft': 440, 'charter': 229, 'man': 901, 'expedi': 530, 'sake': 1302, 'grandest': 654, 'villag': 1637, 'missil': 947, 'tank': 1505, 'sturdi': 1465, 'entitl': 497, 'pleas': 1104, 'knew': 828, 'prudent': 1169, 'eman': 470, 'just': 819, 'restraint': 1258, 'keeper': 823, 'iraq': 801, 'forg': 598, 'afghanistan': 33, 'former': 603, 'tirelessli': 1541, 'lessen': 859, 'nuclear': 1007, 'roll': 1283, 'specter': 1419, 'warm': 1654, 'apolog': 81, 'waver': 1660, 'aim': 43, 'induc': 773, 'slaughter': 1384, 'innoc': 785, 'outlast': 1040, 'patchwork': 1067, 'heritag': 709, 'weak': 1662, 'christian': 239, 'muslim': 973, 'jew': 810, 'hindu': 717, 'nonbeliev': 1000, 'languag': 839, 'tast': 1507, 'swill': 1494, 'segreg': 1328, 'emerg': 474, 'someday': 1400, 'tribe': 1569, 'soon': 1405, 'dissolv': 423, 'smaller': 1390, 'reveal': 1264, 'usher': 1625, 'base': 117, 'mutual': 975, 'sow': 1410, 'blame': 154, 'cling': 256, 'corrupt': 314, 'deceit': 358, 'side': 1366, 'unclench': 1589, 'fist': 578, 'alongsid': 54, 'farm': 555, 'clean': 251, 'flow': 585, 'nourish': 1005, 'starv': 1438, 'hungri': 742, 'rel': 1227, 'plenti': 1108, 'indiffer': 770, 'suffer': 1475, 'outsid': 1043, 'resourc': 1250, 'regard': 1219, 'effect': 464, 'consid': 300, 'gratitud': 657, 'patrol': 1071, 'off': 1018, 'desert': 390, 'distant': 424, 'whisper': 1682, 'guardian': 673, 'embodi': 472, 'willing': 1689, 'inhabit': 782, 'reli': 1229, 'kind': 825, 'stranger': 1454, 'leve': 863, 'break': 170, 'selfless': 1331, 'cut': 341, 'lose': 887, 'darkest': 346, 'firefight': 575, 'stairway': 1429, 'smoke': 1391, 'nurtur': 1008, 'decid': 361, 'instrument': 791, 'honesti': 725, 'curios': 338, 'return': 1262, 'recognit': 1208, 'grudgingli': 671, 'gladli': 640, 'firm': 576, 'noth': 1004, 'satisfi': 1306, 'citizenship': 245, 'race': 1179, 'whose': 1685, '60': 11, 'local': 883, 'restaur': 1255, 'remembr': 1234, 'coldest': 261, 'band': 114, 'huddl': 735, 'campfir': 194, 'ici': 745, 'river': 1277, 'abandon': 12, 'stain': 1428, 'outcom': 1039, 'revolut': 1266, 'doubt': 438, 'order': 1033, 'read': 1194, 'depth': 388, 'virtu': 1640, 'alarm': 46, 'forth': 604, 'current': 339, 'falter': 550, 'fix': 580, 'grace': 651, 'cheney': 230, 'reverend': 1265, 'clergi': 254, 'prescrib': 1132, 'consequenti': 298, 'fulfil': 621, 'second': 1321, 'shipwreck': 1354, 'repos': 1239, 'sabbat': 1293, 'deepest': 369, 'region': 1221, 'simmer': 1372, 'prone': 1163, 'ideolog': 749, 'excus': 521, 'murder': 971, 'multipli': 969, 'destruct': 395, 'cross': 333, 'mortal': 958, 'reign': 1223, 'expos': 533, 'pretens': 1140, 'tyrant': 1583, 'led': 853, 'event': 508, 'sens': 1335, 'conclus': 286, 'increasingli': 767, 'expans': 528, 'matchless': 914, 'imag': 753, 'heaven': 703, 'imper': 757, 'fit': 579, 'slave': 1386, 'mission': 948, 'urgent': 1622, 'polici': 1111, 'democrat': 381, 'goal': 645, 'primarili': 1146, 'though': 1529, 'necessari': 988, 'natur': 983, 'minor': 943, 'aris': 87, 'reflect': 1216, 'custom': 340, 'tradit': 1557, 'style': 1466, 'unwil': 1615, 'attain': 102, 'concentr': 282, 'difficulti': 404, 'influenc': 779, 'unlimit': 1605, 'fortun': 605, 'oppress': 1029, 'consider': 301, 'unwis': 1616, 'persist': 1091, 'clarifi': 249, 'moral': 956, 'pretend': 1139, 'jail': 806, 'dissid': 421, 'chain': 220, 'humili': 739, 'servitud': 1342, 'aspir': 98, 'merci': 930, 'bulli': 184, 'encourag': 479, 'relat': 1228, 'treatment': 1566, 'grudg': 670, 'concess': 285, 'dictat': 400, 'particip': 1060, 'global': 641, 'appeal': 83, 'swiftest': 1493, 'odd': 1017, 'surpris': 1484, 'eventu': 509, 'perman': 1087, 'slaveri': 1388, 'oppressor': 1030, 'repress': 1241, 'prison': 1149, 'exil': 525, 'outlaw': 1041, 'regim': 1220, 'retain': 1259, 'alli': 48, 'counsel': 318, 'primari': 1145, 'concert': 284, 'promot': 1162, 'prelud': 1130, 'patienc': 1069, 'grant': 655, 'dishonor': 418, 'kindl': 826, 'lit': 878, 'feel': 563, 'burn': 185, 'untam': 1612, 'hardest': 690, 'intellig': 794, 'diplomaci': 409, 'idealist': 748, 'death': 354, 'youngest': 1726, 'evil': 516, 'larger': 841, 'essenti': 504, 'unfinish': 1595, 'edg': 461, 'subsist': 1469, 'broader': 177, 'definit': 376, 'motiv': 962, 'homestead': 723, 'gi': 635, 'bill': 148, 'highest': 714, 'standard': 1434, 'ownership': 1049, 'widen': 1686, 'save': 1307, 'insur': 792, 'agent': 37, 'privat': 1150, 'integr': 793, 'edific': 462, 'sinai': 1375, 'sermon': 1338, 'mount': 963, 'koran': 832, 'vari': 1627, 'conduct': 289, 'ennobl': 491, 'surround': 1485, 'unwant': 1614, 'worth': 1713, 'baggag': 112, 'bigotri': 147, 'perspect': 1093, 'includ': 766, 'viewpoint': 1635, 'credit': 325, 'background': 109, 'known': 831, 'felt': 566, 'fellowship': 565, 'whenev': 1678, 'disast': 414, 'unjust': 1604, 'encount': 478, 'captiv': 200, 'wheel': 1677, 'inevitability': 777, 'mankind': 905, 'hunger': 741, 'founder': 611, 'banner': 115, 'meant': 920, 'ebb': 458, 'visibl': 1642, 'direct': 410, 'bell': 134, 'rang': 1187, 'thereof': 1525, 'weari': 1667, 'rehnquist': 1222, 'gore': 649, 'contest': 306, 'slavehold': 1387, 'servant': 1340, 'went': 1673, 'conquer': 295, 'flaw': 583, 'fallibl': 548, 'grand': 653, 'insignific': 786, 'enact': 477, 'halt': 681, 'rock': 1281, 'sea': 1318, 'seed': 1324, 'root': 1285, 'inborn': 765, 'nearli': 985, '225': 8, 'limit': 873, 'hidden': 711, 'circumst': 241, 'seem': 1326, 'contin': 307, 'onward': 1024, 'compass': 275, 'concern': 283, 'forgiv': 600, 'appear': 84, 'undermin': 1591, 'permit': 1088, 'drift': 443, 'tactic': 1499, 'sentiment': 1336, 'accomplish': 19, 'condemn': 288, 'problem': 1152, 'reclaim': 1206, 'apathi': 80, 'prevent': 1142, 'recov': 1209, 'momentum': 954, 'lest': 861, 'invit': 799, 'weapon': 1666, 'mass': 911, 'horror': 731, 'arrog': 93, 'aggress': 38, 'compassion': 276, 'unworthi': 1617, 'whatev': 1676, 'fault': 559, 'abus': 17, 'prolifer': 1160, 'citizens': 244, 'prioriti': 1148, 'diminish': 408, 'hurt': 743, 'mentor': 929, 'touch': 1553, 'pastor': 1065, 'synagogu': 1497, 'mosqu': 960, 'wound': 1715, 'jericho': 809, 'expect': 529, 'scapegoat': 1311, 'deeper': 368, 'option': 1032, 'civic': 246, 'bond': 163, 'uncount': 1590, 'unhonor': 1597, 'comfort': 268, 'easi': 455, 'spectat': 1418, 'miss': 946, 'virginia': 1639, 'statesman': 1440, 'john': 813, 'page': 1051, 'thoma': 1528, 'jefferson': 808, 'ride': 1269, 'whirlwind': 1681, 'sinc': 1376, 'accumul': 21, 'theme': 1524, 'tire': 1540, 'yield': 1723, 'finish': 573}
Encoded Document is:
[[1 1 1 ... 0 0 0]
[0 0 0 ... 1 0 0]
[0 0 0 ... 1 0 1]
[0 0 0 ... 1 0 0]
[0 0 0 ... 1 1 0]
[0 0 0 ... 1 0 0]]
Bigrams#
We could instead generate bigrams with NLTK (Geeks for Geeks), and then index these. This could further increase our accuracy for some applications, but is more complex.
from nltk.util import bigrams
bigram_list = list(bigrams(df["tokens"].iloc[0]))
print("Sample bigrams from Biden's 2021 address:\n")
for bigram in bigram_list[1000:1040]: # Print 40 bigrams from the middle of the speech
print(bigram)
Sample bigrams from Biden's 2021 address:
('care', '?')
('?', 'pay')
('pay', 'mortgag')
('mortgag', '?')
('?', "''")
("''", 'think')
('think', 'famili')
('famili', ',')
(',', 'come')
('come', 'next')
('next', '.')
('.', 'promis')
('promis', ',')
(',', 'get')
('get', '.')
('.', 'answer')
('answer', 'turn')
('turn', 'inward')
('inward', ',')
(',', 'retreat')
('retreat', 'compet')
('compet', 'faction')
('faction', ',')
(',', 'distrust')
('distrust', "n't")
("n't", 'look')
('look', 'like')
('like', 'worship')
('worship', 'way')
('way', "n't")
("n't", 'get')
('get', 'news')
('news', 'sourc')
('sourc', '.')
('.', 'must')
('must', 'end')
('end', 'uncivil')
('uncivil', 'war')
('war', 'pit')
('pit', 'red')
26.7. Conclusion#
In this exercise you”ve learned some basics of how to explore, standardize, tokenize, and index words! This is critical to understand how NLP (including Large Language Models) is possible!