26. Prompt Engineering#
26.1. Pre-Reading#
Objectives#
Explain hardware limits and challenges with LLMs.
Employ simple prompt engineering tactics to produce better LLM results.
26.2. Hardware Expenses#
LLMs take a lot of RAM.
Table: 8-bit quantized LLaMA requirements
Model |
VRAM Used |
Minimum Total VRAM |
Card examples |
RAM/Swap to Load* |
|---|---|---|---|---|
LLaMA-7B |
9.2GB |
10GB |
3060 12GB, 3080 10GB |
24 GB |
LLaMA-13B |
16.3GB |
20GB |
3090, 3090 Ti, 4090 |
32 GB |
LLaMA-30B |
36GB |
40GB |
A6000 48GB, A100 40GB |
64 GB |
LLaMA-65B |
74GB |
80GB |
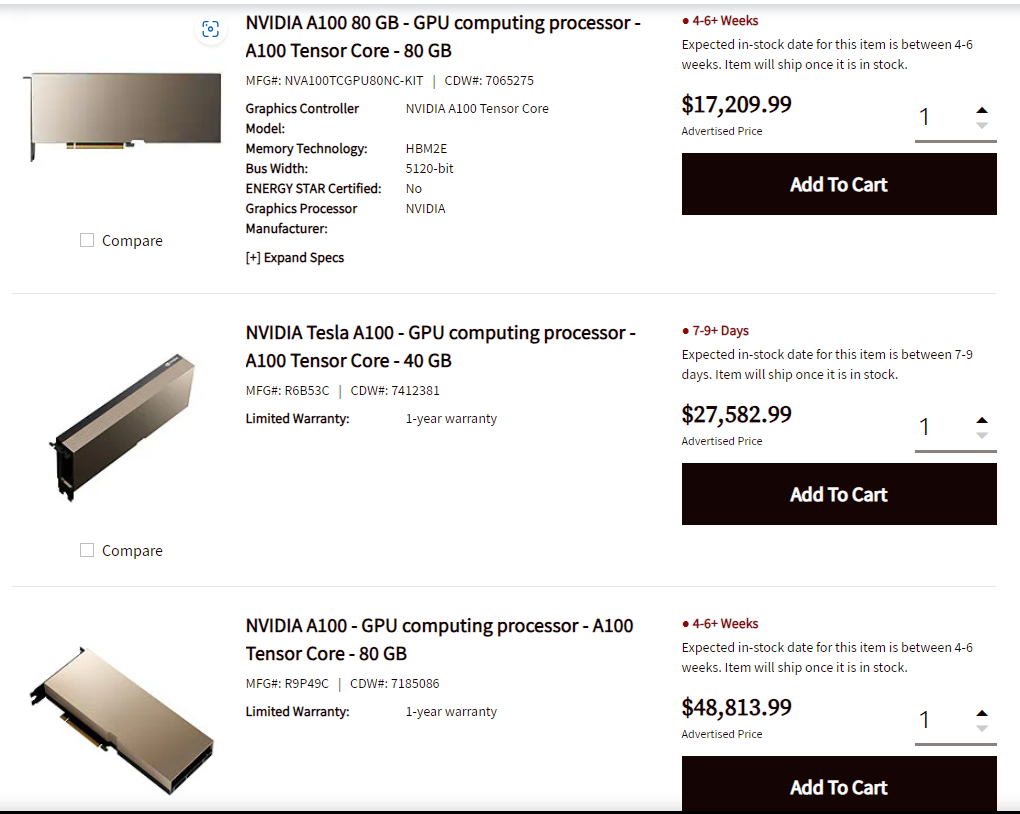
A100 80GB |
128 GB |
Advanced Quantization#
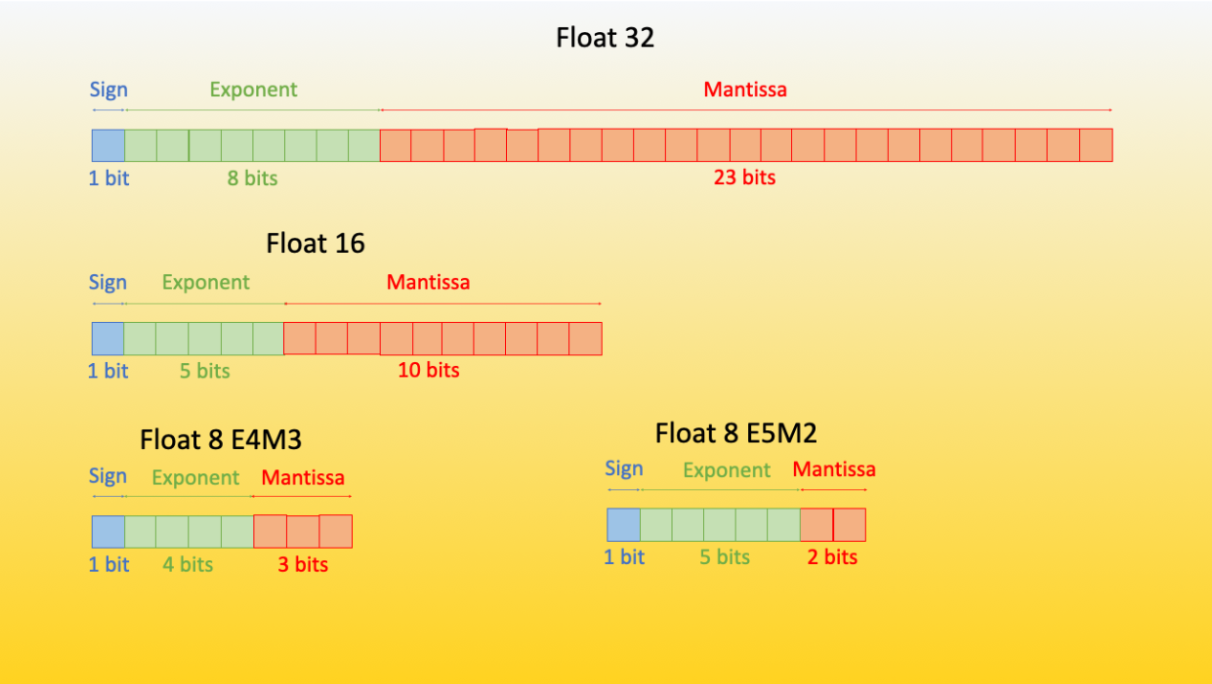
Hugging Face Bits and Bytes can make these models much smaller.
Cost Containment for Generative AI#
From DeepLearning AI’s The Batch newsletter
Microsoft is looking to control the expense of its reliance on OpenAI’s models.
What’s new: Microsoft seeks to build leaner language models that perform nearly as well as ChatGPT but cost less to run, The Information reported.
How it works: Microsoft offers a line of AI-powered tools that complement the company’s flagship products including Windows, Microsoft 365, and GitHub. Known as Copilot, the line is based on OpenAI models. Serving those models to 1 billion-plus users could amount to an enormous expense, and it occupies processing power that would be useful elsewhere. To manage the cost, Microsoft’s developers are using knowledge distillation, in which a smaller model is trained to mimic the output of a larger one, as well as other techniques.
26.3. Prompt Engineering#
Pulled from NVIDIA – An Introduction to LLM: Prompt Engineering and P-Tuning
Zero-shot vs. few-shot#
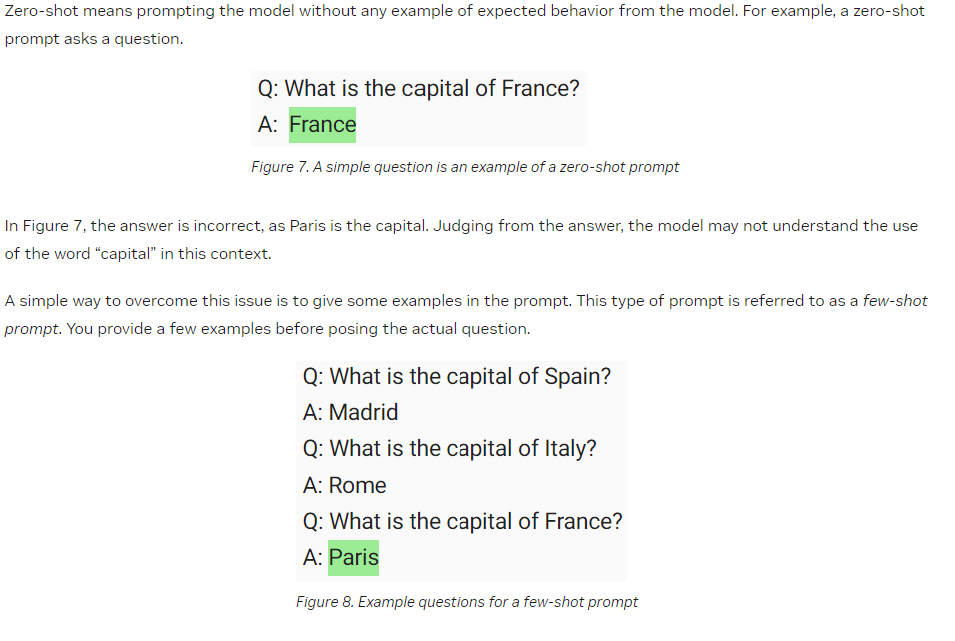
Now time for a live demo!